
One of the defining characteristics of a good programmer is an instinct for keeping implementation details in the correct layer of an application.
That sounds abstract, but it turns out to explain a huge amount of the progress we’ve made in software development over the last twenty-five years.
And nowhere is that clearer than in Perl web development.
Many of us who built web applications during the dotcom boom spent years learning this lesson the hard way.
We wrote CGI programs that:
- parsed HTTP requests
- generated HTML by hand
- connected directly to databases
- embedded SQL inline
- mixed business logic with presentation
- relied on Apache behaviour
- assumed specific filesystem layouts
- and often only worked on one particular server configuration
It all worked. Until it didn’t.
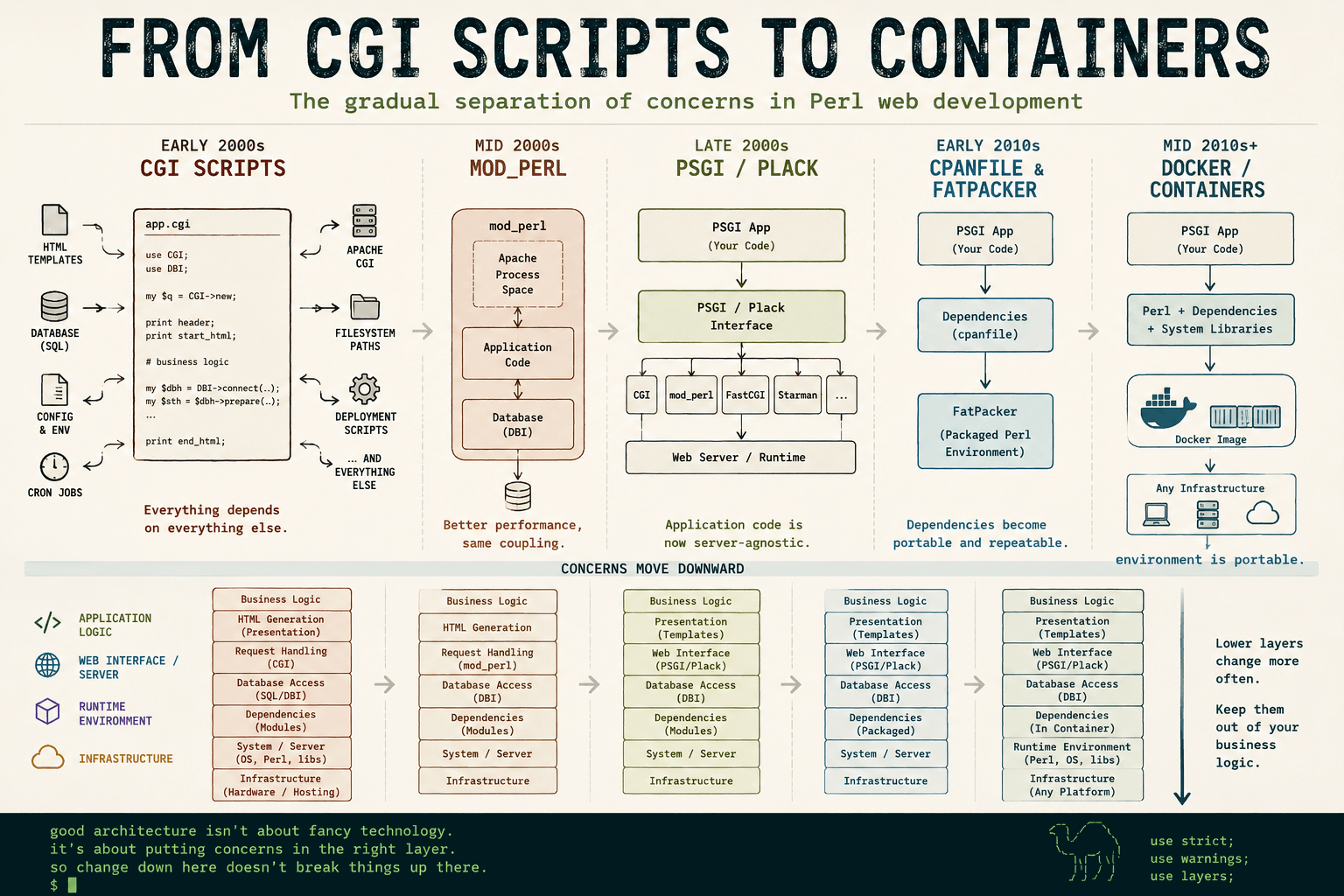
The history of Perl web development is, in many ways, the history of gradually moving implementation details into more appropriate architectural layers.
The Early CGI Years
Early Perl CGI applications were often a single giant script.
You’d open a file and see:
- request handling
- authentication
- HTML generation
- SQL queries
- business logic
- configuration
- deployment assumptions
…all mixed together in a glorious ball of mud.
Something like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
#!/usr/bin/perl use CGI; use DBI; my $cgi = CGI->new; print $cgi->header; print "<html><body>"; my $dbh = DBI->connect( "dbi:mysql:test", "user", "pass" ); my $sth = $dbh->prepare( "select * from users where id = ?" ); $sth->execute($cgi->param('id')); while (my $row = $sth->fetchrow_hashref) { print "<h1>$row->{name}</h1>"; } print "</body></html>"; |
At the time, this felt perfectly normal.
And to be fair, it was a huge step forward from static HTML sites.
But the design had a fundamental problem:
Everything knew too much about everything else.
The application logic knew:
- how HTTP worked
- how HTML worked
- how Apache launched CGI scripts
- how the database worked
- how the operating system was configured
Every concern leaked into every other concern.
That made systems:
- hard to test
- hard to reuse
- hard to deploy
- hard to scale
- and terrifying to change
The First Big Lesson: Put Logic in Libraries
One of the first signs of a developer maturing is the realisation that application logic should live in reusable modules, not in front-end scripts.
Instead of this:
|
1 2 3 |
if ($user->{status} eq 'gold') { $discount = 0.2; } |
being embedded directly in a CGI script, it becomes:
|
1 |
my $discount = $user->discount_rate; |
That sounds like a small change, but architecturally it’s enormous.
Now the business logic lives in a library.
And once that happens, several good things follow automatically.
Multiple Interfaces Become Possible
If the logic is in modules, then:
- a web front-end
- a CLI tool
- a REST API
- a cron job
- a queue worker
…can all use the same underlying code.
The interface layer becomes thin.
The application itself becomes independent of how users interact with it.
That’s a huge increase in flexibility.
Testing Becomes Easier
Testing CGI scripts was always awkward.
Testing modules is straightforward.
You can instantiate objects, call methods, and inspect results without needing a web server or HTTP requests.
The easier code is to test, the more likely it is to be tested.
And tested code tends to survive longer.
Deployment Becomes Safer
Once the core behaviour is isolated from the interface layer, replacing the interface becomes far less risky.
You can redesign the UI without rewriting the application.
That separation is one of the foundations of maintainable software.
The PSGI Revolution
The next big architectural leap in Perl web development came with PSGI and Plack.
Younger developers may not fully appreciate how painful web deployment used to be.
In the early 2000s, moving an application between hosting environments could require substantial rewrites.
- A CGI application worked one way.
- A mod_perl application worked another way.
- FastCGI had its own quirks.
- Embedded Apache handlers behaved differently again.
Many Perl developers spent years repeatedly rewriting applications simply because deployment environments changed.
That was madness.
The deployment model is an operational concern.
It should not affect application architecture.
PSGI fixed this by defining a standard interface between web applications and web servers.
The core idea was beautifully simple:
A web application is just a function that receives an environment and returns a response.
Once that abstraction existed, applications no longer cared whether they were running:
- as CGI
- under mod_perl
- inside FastCGI
- under Starman
- behind nginx
- on a development laptop
- or inside a cloud container
The deployment details moved down a layer.
Exactly where they belonged.
This was one of the most important architectural improvements Perl web development ever made.
And it reflected a broader truth:
Good abstractions stop lower-level implementation details leaking upward.
The Transitional Era: FatPacker and cpanfile
There was also an interesting intermediate stage between traditional Perl deployments and full containerisation.
For years, one of the hardest parts of deploying Perl applications was dependency management.
You’d move an application to a new server and discover:
- the wrong module version
- missing XS libraries
- incompatible Perl versions
- or an entire dependency tree that worked perfectly on the developer’s machine and nowhere else
Large parts of Perl deployment culture evolved around coping with this problem.
Tools like cpanfile improved things by making dependencies explicit and reproducible.
Instead of vaguely documenting requirements in a README, applications could formally declare:
|
1 2 3 |
requires 'Dancer2'; requires 'DBIx::Class'; requires 'Template'; |
That may seem obvious now, but it was a major improvement in deployment reliability.
Then tools like App::FatPacker went even further by packaging dependencies directly alongside applications.
Instead of relying on the target server’s Perl environment, applications could carry much of their runtime context with them.
These tools didn’t completely solve deployment portability:
- system libraries still mattered
- Perl versions still mattered
- operating system differences still mattered
…but they represented an important shift in thinking.
The industry was gradually realising that:
- deployment environments were part of the application
- reproducibility mattered
- and infrastructure assumptions needed to be controlled
Containers eventually pushed this idea to its logical conclusion by packaging not just Perl dependencies, but the entire runtime environment.
In hindsight, tools like cpanfile and FatPacker were stepping stones toward modern container-based deployment models.
Containers Are the Same Idea Again
Docker and containers are simply the same architectural principle repeated one layer lower.
Before containers, deployments were often fragile and highly environment-specific.
Applications depended on:
- particular Linux distributions
- specific Perl versions
- installed system libraries
- hand-configured servers
- undocumented setup steps
Developers became experts in “works on my machine”.
Operations teams became experts in swearing.
Containers changed the model.
Instead of deploying:
- source code
…you deploy:
- a complete runtime environment
Now the application no longer cares whether it runs:
- on bare metal
- on a VPS
- in Kubernetes
- in ECS
- in Cloud Run
- or on someone’s laptop
Again:
- infrastructure concerns move downward
- application concerns stay upward
The boundaries become cleaner.
The Pattern Repeats Everywhere
Once you notice this pattern, you see it throughout software engineering.
Templates
Template systems separate:
- presentation
from
- application logic
HTML should not contain database code.
Business logic should not contain giant blobs of HTML.
ORMs and Database Layers
DBI separates applications from database engines.
ORMs separate applications from raw SQL structure.
Again:
- implementation details move downward
Configuration
Configuration belongs outside code.
Deployment-specific values should not be embedded in applications.
APIs
Clients should not care whether data comes from:
- PostgreSQL
- Redis
- another service
- a queue
- flat files
- or magic elves
That’s the implementation’s problem.
The Goal Is Not Abstraction for Its Own Sake
Of course, experienced developers also know that abstractions can become ridiculous.
Some abstractions simplify systems.
Others merely hide complexity behind six additional layers of YAML.
Joel Spolsky’s “Law of Leaky Abstractions” remains painfully relevant.
The goal is not abstraction itself.
The goal is to isolate genuinely volatile details.
Good abstractions protect systems from change.
Bad abstractions merely obscure reality.
The Real Skill
The deeper lesson here is that software architecture is largely about deciding:
“What belongs where?”
Experienced developers develop an instinct for:
- which details are likely to change
- which layers should know about which concerns
- and where boundaries should exist
That instinct is often more important than language choice, frameworks, or technology stacks.
And if you spent the early 2000s rewriting CGI applications to run under mod_perl, you probably learned that lesson the hard way.

Excellent article. So how does AI fit into all of this? Well, I believe that this separation of concerns that you have described here is exactly what you need to feed to AI in order to get usable results. The worst thing that you can do is just to tell AI, “Build me this.” Instead, you’re better off asking AI to build each piece and then create the APIs between each piece. We are not yet at the point where we can treat the output of an AI the same way we treat the output of a compiler.
“We are not yet at the point where we can treat the output of an AI the same way we treat the output of a compiler.”
That will always be true because there are many problems which simply *can’t* have a deterministic answer, so I think AI (LLM-based, at least) will always have this. However, the primary complaint about AI (it’s non-deterministic and stochastic) is also true of humans. Once the code is written, whether by AI or humans, the output of the compiler won’t change.
It’s the *decisions* going into that code which change and they probably always will. Give 100 humans the same programming problem and you’ll get 100 variations on a theme. Even if all of them ultimately do the same thing, how they get there will be different.
In reality, we can corral many of the AI problems by having amazing test suites, great documentation, and regular architecture reviews (and fixing the issues we find). I’ve found that when devs *apply the same strict requirements on AI that they should be following*, you get much, much better output. There are still some open questions about scale, but the approach is clear: disciplined developers who use AI and enforce the same discipline get great results.
Nice article!
But I don’t get the cpanfile thing. Didn’t we all have perfectly good requirements in Makefile.PL and Build.PL years before cpanfile was proposed?
cpanfile is still an artifact created barely used anywhere here when running Makefile.PL, cpanm might use when –installdeps but not so sure actually.
You’re absolutely right that Perl already had dependency declarations in
Makefile.PLandBuild.PLlong beforecpanfile.The difference is mostly about audience and intent.
Makefile.PLexists primarily as part of a CPAN distribution build/install process. It’s tightly tied to ExtUtils::MakeMaker and the traditional CPAN toolchain. Historically, that often meant:That works perfectly for reusable libraries intended for CPAN. But many modern Perl web applications aren’t really “installable CPAN distributions”. They’re applications to be deployed.
cpanfilegave us a lightweight, declarative way to say:…without needing all the surrounding CPAN packaging machinery.
That made it particularly useful for:
It also decoupled dependency declaration from installer implementation.
Instead of:
you get:
which is a cleaner separation of concerns.
And tools like
cpanm --installdeps .could consume that very easily.So I think of
cpanfileless as “inventing dependency management” and more as:I would agree that “What belongs where?” is a fundamental question, which can be surprisingly hard to answer at times. However, iterate thru a few releases and you’ll start to work out the answers.
We’ve mostly moved thru your chart over time (skipping a few small parts), except for that last step to containers. That includes having to make our own form of FatPacker, because we need a “deb file” with all supporting Perl modules for application installation.
Our group gets asked about once a year, “What about putting the product in containers instead of everything on a single server?” When I ask “Why?” the answer is usually in the “Because it’s the current trend” type of answer. I’ve never heard a truly good reason for doing it *for our Perl/DB/CGI product*. (Note, we run in a heavily controlled environment and a cloud is something that’s outside in the sky.) I know your blog is talking in generalities, but I think that at times people (including developers) get swept up in “current trends” and don’t stop to think about what’s right for the work they’re doing. Containers do make sense in a number of situations, but that is *not all* situations.
Containers still tie you to a specific Linux version, Perl version, module versions, lib versions, etc. just like installing on “bare metal” (if that was not documented and installation was not automated then shame on you and go fix it). Containers allow you to move that virtual install chunk around…maybe that’s useful or maybe it’s not. Containers would cause a lot of bloat for us because of duplicated code into all 9 or 10 containers for our product — there is a lot of shared module code. Containers also introduce extra overhead; sure it’s very small, but it is there especially in the network layer and our product throws around a lot of data over the network, externally and between all of the possible containers.
The point is containers have pluses and minuses and you have to look at the whole scorecard to know if they’re right for you. 🙂 It’s probable that containers are a good end goal for a lot of people; for at least a few of us they don’t offer anything useful. Although, the new class stuff that’s making its way into Perl5, that looks like it will be useful…
I think we’re mostly in agreement 🙂
I certainly wasn’t trying to argue that containers are the right answer for every application. There are plenty of situations where a traditional deployment model is simpler and entirely appropriate.
My point was more about architectural layering than any specific technology.
For example, I wouldn’t justify containers with “because it’s the trend” either. The advantages I usually hear are things like:
Whether those benefits outweigh the costs depends entirely on the application.
I also agree that containers don’t magically remove version dependencies. In fact, one of their strengths is that they preserve them. If my application requires a particular Linux distribution, Perl version and set of libraries, then having those versions explicitly captured in a container image is often a feature rather than a bug.
Perhaps a better way of putting it is that containers don’t eliminate environmental dependencies; they make them explicit, reproducible and portable.
And that’s really the connection I was trying to make in the article. Just as PSGI separated application code from web-server details, containers separate application deployment from the characteristics of a particular machine. Whether that abstraction is worth using is, of course, a separate question.
This article beautifully captures the 25-year journey of software architecture, and it hits incredibly close to home. Back in the early 2000s, I created CGI::Prototype for the University at Buffalo and my GeekCruises client to solve exactly what you described—bringing a class-based structure and a primitive state engine to multi-page forms so the state passing became transparent to the developer.
It’s fascinating how these patterns come full circle. Today, I work heavily with Flutter, and we are fighting the exact same fundamental architectural battles regarding UI state management. Moving toward lightweight reactive primitives like Signals and the SignalProvider class feels conceptually identical to the slot inheritance mechanics we used in CGI::Prototype decades ago. The tech stacks change, but the core discipline of ‘What belongs where?’ and making the view a clean reflection of the state graph remains exactly the same.
Which is, of course, where greybeards like you and I can bring value to a project. We have experience of solving these problems over decades. Only the syntax has changed.