At the end of my last post, we had a structure in place that used GitHub Actions to run a workflow every time a change was committed to the PPC repository. That workflow would rebuild the website and publish it on GitHub Pages.
All that was left for us to do was to write the middle bit – the part that actually takes the contents of the repo and creates the website. This involves writing some Perl.
There are three types of pages that we want to create:
- The PPCs themselves, which are in Markdown and need to be converted to HTML pages
- There are a few other pages that describe the PPC process, also in Markdown, which should be converted to HTML
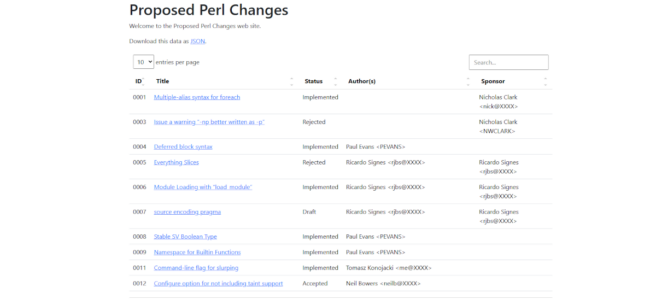
- An index page which should contain links to the other pages. This page should include a table listing various useful details about the PPCs so visitors can quickly find the ones they want more information on
I’ll be using the Template Toolkit to build the site, with a sprinkling of Bootstrap to make it look half-decent. Because there is a lot of Markdown-to-HTML conversion, I’ll use my Template::Provider::Pandoc module which uses Pandoc to convert templates into different formats.
Parsing PPCs and extracting data
The first thing I did was parse the PPCs themselves, extracting the relevant information. Luckily, each PPC has a “preamble” section containing most of the data we need. I created a basic class to model PPCs which included a really hacky parser to extract this information and create a object of the class.
Building the site
This class abstracts away a lot of the complexity which means the program that actually builds the site is less than eighty lines of code. Let’s look at it in a bit more detail:
|
1 2 3 4 5 6 7 8 9 |
#!/usr/bin/perl use v5.38; use JSON; use File::Copy; use Template; use Template::Provider::Pandoc; use PPC; |
There’s nothing unusual in the first few lines. We’re just loading the modules we’re using. Note that use v5.38 automatically enables strict and warnings, so we don’t need to load them explicitly.
|
1 2 3 4 |
my @ppcs; my $outpath = './web'; my $template_path = [ './ppcs', './docs', './in', './ttlib' ]; |
Here, we’re just setting up some useful variables. @ppcs will contain the PPC objects that we create. One potential clean-up here is to reduce the size of that list of input directories.
|
1 2 3 4 |
my $base = shift || $outpath; $base =~ s/^\.//; $base = "/$base" if $base !~ m|^/|; $base = "$base/" if $base !~ m|/$|; |
This is a slightly messy hack that is used to set a <base> tag in the HTML.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
my $provider = Template::Provider::Pandoc->new({ INCLUDE_PATH => $template_path, }); my $tt = Template->new({ LOAD_TEMPLATES => [ $provider ], INCLUDE_PATH => $template_path, OUTPUT_PATH => $outpath, RELATIVE => 1, WRAPPER => 'page.tt', VARIABLES => { base => $base, } }); |
Here, we’re setting up our Template Toolkit processor. Some of you may not be familiar with using a Template provider module. These modules change how TT retrieves templates: if the template has an .md extension, then the text is passed though Pandoc to convert it from Markdown to HTML before it’s handed to the template processor. It’s slightly annoying that we need to pass the template include path to both the provider and the main template engine.
|
1 2 3 4 5 6 7 |
for (<ppcs/*.md>) { my $ppc = PPC->new_from_file($_); push @ppcs, $ppc; $tt->process($ppc->in_path, {}, $ppc->out_path) or warn $tt->error; } |
This is where we process the actual PPCs. For each PPC we find in the /ppcs directory, we create a PPC object, store that in the @ppcs variable and process the PPC document as a template – converting it from Markdown to HTML and writing it to the /web directory.
|
1 2 3 4 5 6 |
my $vars = { ppcs => \@ppcs, }; $tt->process('index.tt', $vars, 'index.html') or die $tt->error; |
Here’s where we process the index.tt file to generate the index.html for our site. Most of the template is made up of a loop over the @ppcs variable to create a table of the PPCs.
|
1 2 3 4 5 6 7 |
for (<docs/*.md>) { s|^docs/||; my $out = s|\.md|/index.html|r; $tt->process($_, {}, $out) or die $tt->error; } |
There are a few other documents in the /docs directory describing the PPC process. So in this step, we iterate across the Markdown files in that directory and convert each of them into HTML. Unfortunately, one of them is the template.md which is intended to be used as the template for new PPCs – so it would be handy if that one wasn’t converted to HTML. That’s something to think about in the future.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
mkdir 'web/images'; for (<images/*>) { copy $_, "web/$_"; } if (-f 'in/style.css') { copy 'in/style.css', 'web/style.css'; } if (-f 'CNAME') { copy 'CNAME', "web/CNAME"; } |
We’re on the home straight now. And this section is a bit scrappy. You might recall from the last post that we’re building the website in the /web directory. And there are a few other files that need to be copied into that directory in order that they are then deployed to the web server. So we just copy files. You might not know what a CNAME file is – it’s the file that GitHub Pages uses to tell their web server that you’re serving your website from a custom domain name.
|
1 2 3 4 5 6 7 |
my $json = JSON->new->pretty->canonical->encode([ map { $_->as_data } @ppcs ]); open my $json_fh, '>', 'web/ppcs.json' or die $!; print $json_fh $json; |
And, finally, we generate a JSON version of our PPCs and write that file to the /web directory. No-one asked for this, but I thought someone might find this data useful. If you use this for something interesting, I’d love to hear about it.
Other bits and pieces
A few other bits and pieces to be aware of.
- I use a page wrapper to ensure that every generated page has a consistent look and feel
- The navigation in the page wrapper is hard-coded to contain links to the pages in
/docs. It would make sense to change that so it’s generated from the contents of that directory - I used a Javascript project called Simple Datatables to turn the main table into a data table. That means it’s easy to sort, page and filter the data that’s displayed
- There’s a basic hack that hides the email addresses when they appear in the main table. But it’s currently not applied to the PPC pages themselves. I’ve idly contemplated writing a TT filter that would be called something like Template::Filter::RemoveEmailAddresses
In conclusion
But there you are. That’s the system that I knocked together in a few hours a couple of weeks ago. As I mentioned in the last post, the idea was to make the PPC process more transparent to the Perl community outside of the Perl 5 Porters and the Perl Steering Council. I hope it achieves that and, further, I hope it does so in a way that keeps out of people’s way. As soon as someone updates one of the documents in the repository, the workflow will kick in and publish a new version of the website. There are a few grungy corners of the code and there are certainly some improvements that can be made. I’m hoping that once the pull request is merged, people will start proposing new pull requests to add new features.
