Many thanks to Dave Cross for providing an initial implementation of a PPC index page.
Maybe I should explain that in a little more detail. There’s a lot of detail, so it will take a couple of blog posts.
About two weeks ago, I got a message on Slack from Phillippe Bruhat, a member of the Perl Steering Council. He asked if I would have time to look into building a simple static site based on the GitHub repo that stores the PPCs that are driving a lot of Perl’s development. The PSC thought that reading these important documents on a GitHub page wasn’t a great user experience and that turning it into a website might lead to more people reading the proposals and, hence, getting involved in discussions about them.
I guess they had thought of me as I’ve written a bit about GitHub Pages and GitHub Actions over the last few years and these were exactly the technologies that would be useful in this project. In fact, I have already created a website that fulfills a similar role for the PSC meeting minutes – and I know they know about that site because they’ve been maintaining it themselves for several months.
I was about to start working with a new client, but I had a spare day, so I said I’d be happy to help. And the following day, I set to work.
Reviewing the situation
I started by looking at what was in the repo.
All of these documents were in Markdown format. The PPCs seemed to have a pretty standardised format.
Setting a target
Next, I listed what would be essential parts of the new site.
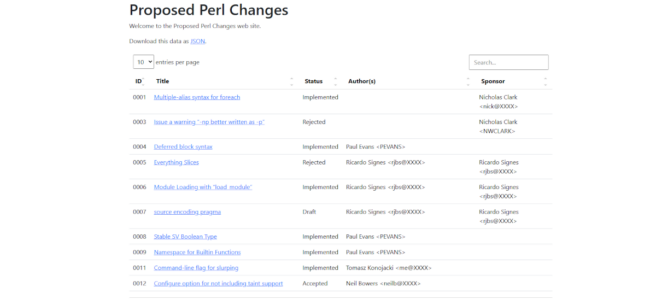
- An index page containing a list of the PPCs – which links to a page for each of the PPCs
- The PPCs, converted to HTML
- The other documents, also converted to HTML
- The site should be automatically rebuilt whenever a change is made to any of the input files
This is exactly the kind of use case that a combination of GitHub Pages and GitHub Actions is perfect for. Perhaps it’s worth briefly describing what those two GitHub features are.
Introducing GitHub Pages
GitHub Pages is a way to run a website from a GitHub repo. The feature was initially introduced to make it easy to run a project website alongside your GitHub repo – with the files that make up the website being stored in the same repo as the rest of your code. But, as often happens with useful features, people have been using the feature for all sorts of websites. The only real restriction is that it only supports static sites – you cannot use GitHub’s servers to run any kind of back-end processing.
The simplest way to run a GitHub Pages website is to construct it manually, put the HTML, CSS and other files into a directory inside your repo called /docs, commit those files and go to the “Settings -> Pages” settings for your repo to turn on Pages for the repo. Within minutes your site will appear at the address USERNAME.github.repo/REPONAME. Almost no-one uses that approach.
The most common approach is to use a static site builder to build your website. The most popular is Jekyll – which is baked into the GitHub Pages build/deploy cycle. You edit Markdown files and some config files. Then each time you commit a change to the repo, GitHub will automatically run Jekyll over your input files, generate your website and deploy that to its web servers. We’re not going to do that.
We’ll use the approach I’ve used for many GitHub Pages sites. We’ll use GitHub Actions to do the equivalent of the “running Jekyll over your input files to generate your website” step. This gives us more flexibility and, in particular, allows us to generate the website using Perl.
Introducing GitHub Actions
GitHub Actions is another feature that was introduced with one use case in mind but which has expanded to be used for an incredible range of ideas. It was originally intended for CI/CD – a replacement for systems like Jenkins or Travis CI – but that only accounts for about half of the things I use it for.
A GitHub Actions run starts in response to various triggers. You can then run pretty much any code you want on a virtual machine, generating useful reports, updating databases, releasing code or (as in this case) generating a website.
GitHub Actions is a huge subject (luckily, there’s a book!) We’re only going to touch on one particular way of using it. Our workflow will be:
- Wait for a commit to the repo
- Then regenerate the website
- And publish it to the GitHub Pages web servers
Making a start
Let’s make a start on creating a GitHub Actions workflow to deal with this. Workflows are defined in YAML files that live in the .github/workflows directory in our repo. So I created the relevant directories and a file called buildsite.yml.
There will be various sections in this file. We’ll start simply by defining a name for this workflow:
|
1 |
name: Generate website |
The next section tells GitHub when to trigger this workflow. We want to run it when a commit is pushed to the “main” branch. We’ll also add the “workflow_dispatch” trigger, which allows us to manually trigger the workflow – it adds a button to the workflow’s page inside the repo:
|
1 2 3 4 |
on: push: branches: 'main' workflow_dispatch: |
The main part of the workflow definition is the next section – the one that defines the jobs and the individual steps within them. The start of that section looks like this:
|
1 2 3 4 5 6 7 8 9 10 11 |
jobs: build: runs-on: ubuntu-latest container: perl:latest steps: - name: Perl version run: perl -v - name: Checkout uses: actions/checkout@v4 |
The “build” there is the name of the first job. You can name jobs anything you like – well anything that can be the name of a valid YAML key. We then define the working environment for this job – we’re using a Ubuntu virtual machine and on that, we’re going to download and run the latest Perl container from the Docker Hub.
The first step isn’t strictly necessary, but I like to have a simple but useful step to ensure that everything is working. This one just prints the Perl version to the workflow log. The second step is one you’ll see in just about every GitHub Actions workflow. It uses a standard, prepackaged library (called an “action”) to clone the repo to the container.
The rest of this job will make much more sense once I’ve described the actual build process in my next post. But here it is for completeness:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
- name: Install pandoc and cpanm run: apt-get update && apt-get install -y pandoc cpanminus - name: Install modules run: | cpanm --installdeps --notest . - name: Get repo name into environment run: | echo "REPO_NAME=${GITHUB_REPOSITORY#$GITHUB_REPOSITORY_OWNER/}" >> $GITHUB_ENV - name: Create pages env: PERL5LIB: lib GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }} run: | mkdir -p web perl bin/build $REPO_NAME - name: Update pages artifact uses: actions/upload-pages-artifact@v3 with: path: web/ |
Most of the magic (and all of the Perl – for those of you who were wondering) happens in the “Create pages” step. If you can’t wait until the next post, you can find the build program and the class it uses in the repo.
But for now, let’s skim over that and look at the final step in this job. That uses another pre-packaged action to build an artifact (which is just a tarball) which the next job will deploy to the GitHub Pages web server. You can pass it the name of a directory and it will build the artifact from that directory. So you can see that we’ll be building the web pages in the web/ directory.
The second (and final) job is the one that actually carries out the deployment. It looks like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
deploy: needs: build permissions: pages: write id-token: write environment: name: github-pages url: ${{ steps.deployment.outputs.page_url }} runs-on: ubuntu-latest steps: - name: Deploy to GitHub Pages id: deployment uses: actions/deploy-pages@v4 |
It uses another standard, pre-packaged action and most of the code here is configuration. One interesting line is the “need” key. That tells the workflow engine that the “build” job needs to have completed successfully before this job can be run.
But once it has run, the contents of our web/ directory will be on the GitHub Pages web server and available for our adoring public to read.
All that is left is for us to write the steps that will generate the website. And that is what we’ll be covering in my next post.
Oh, and if you want to preview the site itself, it’s at https://davorg.dev/PPCs/ and there’s an active pull request to merge it into the main repo.
