Back in January, I wrote a blog post about adding JSON-LD to your web pages to make it easier for Google to understand what they were about. The example I used was my ReadABooker site, which encourages people to read more Booker Prize shortlisted novels (and to do so by buying them using my Amazon Associate links).
I’m slightly sad to report that in the five months since I implemented that change, visits to the website have remained pretty much static and I have yet to make my fortune from Amazon kickbacks. But that’s ok, we just use it as an excuse to learn more about SEO and to apply more tweaks to the website.
I’ve been using the most excellent ARefs site to get information about how good the on-page SEO is for many of my sites. Every couple of weeks, ARefs crawls the site and will give me a list of suggestions of things I can improve. And for a long time, I had been putting off dealing with one of the biggest issues – because it seemed so difficult.
The site didn’t have enough text on it. You could get lists of Booker years, authors and books. And, eventually, you’d end up on a book page where, hopefully, you’d be tempted to buy a book. But the book pages were pretty bare – just the title, author, year they were short-listed and an image of the cover. Oh, and the all-important “Buy from Amazon” button. AHrefs was insistent that I needed more text (at least a hundred words) on a page in order for Google to take an interest in it. And given that my database of Booker books included hundreds of books by hundreds of authors, that seemed like a big job to take on.
But, a few days ago, I saw a solution to that problem – I could ask ChatGPT for the text.
I wrote a blog post in April about generating a daily-updating website using ChatGPT. This would be similar, but instead of writing the text directly to a Jekyll website, I’d write it to the database and add it to the templates that generate the website.
Adapting the code was very quick. Here’s the finished version for the book blurbs.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 |
#!/usr/bin/env perl use strict; use warnings; use builtin qw[trim]; use feature 'say'; use OpenAPI::Client::OpenAI; use Time::Piece; use Encode qw[encode]; use Booker::Schema; my $sch = Booker::Schema->get_schema; my $count = 0; my $books = $sch->resultset('Book'); while ($count < 20 and my $book = $books->next) { next if defined $book->blurb; ++$count; my $blurb = describe_title($book); $book->update({ blurb => $blurb }); } sub describe_title { my ($book) = @_; my ($title, $author) = ($book->title, $book->author->name); my $debug = 1; my $api_key = $ENV{"OPENAI_API_KEY"} or die "OPENAI_API_KEY is not set\n"; my $client = OpenAPI::Client::OpenAI->new; my $prompt = join " ", 'Produce a 100-200 word description for the book', "'$title' by $author", 'Do not mention the fact that the book was short-listed for (or won)', 'the Booker Prize'; my $res = $client->createChatCompletion({ body => { model => 'gpt-4o', # model => 'gpt-4.1-nano', messages => [ { role => 'system', content => 'You are someone who knows a lot about popular literature.' }, { role => 'user', content => $prompt }, ], temperature => 1.0, }, }); my $text = $res->res->json->{choices}[0]{message}{content}; $text = encode('UTF-8', $text); say $text if $debug; return $text; } |
There are a couple of points to note:
- I have DBIC classes to deal with the database interaction, so that’s all really simple. Before running this code, I added new columns to the relevant tables and re-ran my process for generating the DBIC classes
- I put a throttle on the processing, so each run would only update twenty books – I slightly paranoid about using too many requests and annoying OpenAI. That wasn’t a problem at all
- The hardest thing (not that it was very hard at all) was to tweak the prompt to give me exactly what I wanted
I then produced a similar program that did the same thing for authors. It’s similar enough that the next time I need something like this, I’ll spend some time turning it into a generic program.
I then added the new database fields to the book and author templates and re-published the site. You can see the results in, for example, the pages for Salman Rushie and Midnight’s Children.
I had one more slight concern going into this project. I pay for access to the ChatGPT API. I usually have about $10 in my pre-paid account and I really had no idea how much this was going to cost me. I needed have worried. Here’s a graph showing the bump in my API usage on the day I ran the code for all books and authors:
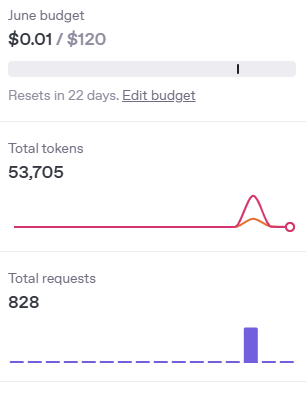
But you can also see that my total costs for the month so far are $0.01!
So, all-in-all, I call that a success and I’ll be using similar techniques to generate content for some other websites.
