Tag: programming
-
The Joy of Prefetch
If you heard me speak at YAPC or you’ve had any kind of conversation with me over the last few weeks then it’s likely you’ve heard me mention the secret project that I’ve been writing for my wife’s school. To give you a bit of background, there’s one afternoon a week where the students at…
-
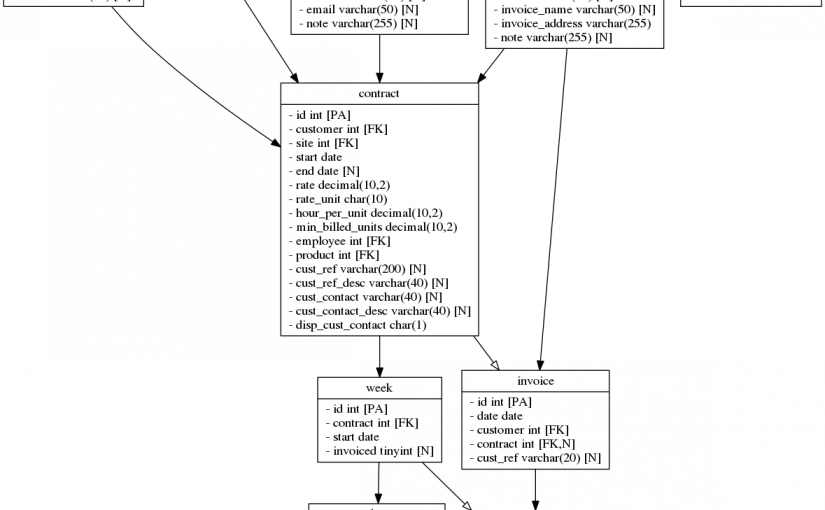
Driving a Business with Perl
I’ve been a freelance programmer for over twenty years. One really important part of the job is getting paid for the work I do. Back in 1995 when I started out there wasn’t all of the accounting software available that you get now and (if I recall correctly) the little that was available was all…
-
Subroutines and Ampersands
I’ve had this discussion several times recently, so I thought it was worth writing a blog post so that I have somewhere to point people the next time it comes up. Using ampersands on subroutine calls (&my_sub or &my_sub(…)) is never necessary and can have potentially surprising side-effects. It should, therefore, never be used and…
-
Dev Assistant
A couple of days ago, I updated to my laptop to Fedora 21. One of the new features was an application called DevAssistant which claimed that: It does not matter if you only recently discovered the world of software development, or if you have been coding for two decades, there’s always something DevAssistant can do…
-
“I Do Not Want To Use Any Modules”
Almost every day on the Perl groups on LinkedIn (or Facebook, or StackOverflow, or somewhere like that) I see a question that includes the restriction “I do not want to use any modules”. There was one on LinkedIn yesterday. He wanted to create a MIME message to pass to sendmail, but he didn’t want to install…