Despite valiant attempts by the marketing departments of Microsoft and Sun, CGI is still the most commonly used architecture for creating dynamic content on the World Wide Web. In this series of tutorials we’ll look at how to write CGI programs. The third tutorial in the series looks at some more advanced topics in CGI programming.
This article was originally published by Linux Format in June 2001.
Please note that these tutorials are only left here for historical interest. If you are writing new web applications with Perl these days, you should be considering something based on PSGI and Plack or even something using raw PSGI.
Introduction
In the last couple of articles we’ve covered just about everything you need to know in order to write simple and secure CGI programs. This month we’ll take a look at a couple of techniques that will make it easier for you to write more complex programs – storing session information and separating your HTML from your Perl code.
Persistent Data
Whenever you request a page from a web site you use a networking protocol called HTTP (Hyper Text Transfer Protocol). This protocol defines the format of the data that your browser sends to the web server and also the data that the server returns to your browser. This protocol was designed to be as simple as possible. One of the downsides of its simplicity is that it is “stateless”.
What this means is that each request to the server is completely independent of any other request. If you request a page from a web site and then click on a link request another page, the second request has nothing in it to associate it with the first request. Each page request needs to be seen as a separate transaction between the browser and the server.
If you’re simply requesting single pages this is not a problem. It can, however, make things difficult when we’re tring to write complex CGI programs. For example, imagine a shopping cart program. When visitors come to buy goods from the web site, they visit a number of different pages choosing the things they want to buy. When they have finished choosing their purchases they expect to see a final shopping basket before they can place their order. Because of the stateless nature of HTTP, the shopping cart program needs to do extra work to keep track of all of this “session” information.
People have invented a number of ways to deal with this problem. Let’s take a look at some of the most common.
Hidden fields
HTML has a type of form input tag which doesn’t appear in the displayed page. The tag looks like this
|
1 |
<input type="hidden" name="secret" value="some secret data"> |
Although this field isn’t displayed, it is passed to the CGI program that processes the form in exactly the same way as visible fields are. This means that you can access the data like this
|
1 |
my $secret = param('secret'); |
So if your page is generated by a CGI program and you want to use data from the previous pages but not show it to the use, you can make use of hidden fields.
It’s worth noting that although hidden fields aren’t displayed in the browser, they are part of the HTML for the page so the use can see them by viewing the source of the page. Don’t assume that hidden fields are really hidden.
Path info
You will sometimes see a URL that looks a bit like this:
|
1 |
http://www.some.server.com/cgi-bin/program.pl/some/other/data |
On first glance this looks a bit strange. program.pl is obviously a CGI program, but what’s that extra data that looks a bit like a file path on the end? This is another part of the CGI specification that we haven’t mentioned yet. The extra data is called the “Path Info” and its contents are passed into the CGI program in an environment variable called PATH_INFO. In a Perl program that value can be accessed using the variable $ENV{PATH_INFO}. CGI.pm also has a function called “path_info()” that does the same thing.
Here’s a simple program that illustrates how to access the path info.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
#!/usr/bin/perl -wT use strict; use CGI ':standard'; my $info = path_info; print header, start_html, h1('Path Info'), p('Here are the contents of $ENV{PATH_INFO}'); my @info = split /\//, $info; print ul(li([@info])); print end_html; |
The figure shows the result of running this program using the URL
|
1 |
http://localhost/cgi-bin/path_info.pl/this/is/some/data/in/path/info |
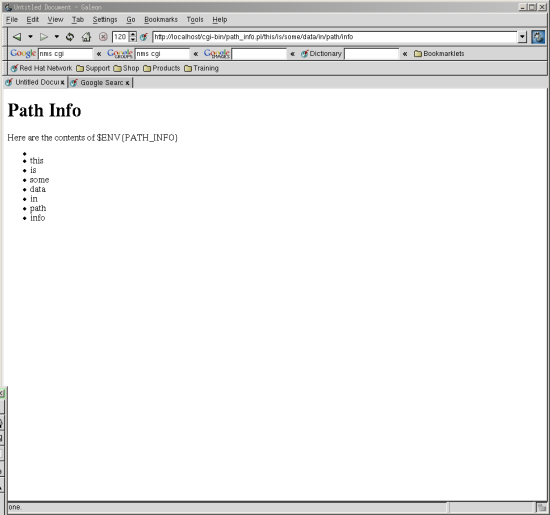
Displaying PATH_INFO
This obviously isn’t very effective for passing on large amounts of data, but if you only have a few items then it can be quite effective.
Cookies
Neither of the the previous solutions address the problem of what happens if the user leaves your web site and returns later. For either hidden fields or path info to work, you need an unbroken chain of web pages that you have control of. Netscape came up with a solution to this problem which they called “magic cookies”. Nowadays, they are just called “cookies” but the basic idea has remained the same. Cookies allow a web site to store small pieces of data on the client machine (i.e. at the browser end of the transaction). When the use visits your web site again, the browser will automatically send all cookies belonging to your site back to the server as part of the HTTP header. A cookie therefore has a name and a value (very much like a CGI parameter), a domain that it is associated with and an expiry time. It is also possible to associate a path with a cookie so that it’s only used for a certain area of your site.
CGI.pm contains a function “cookie” which allows you to get and set cookies. Let’s take a look at a sample program which uses it.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
#!/usr/bin/perl -wT use strict; use CGI ':standard'; my $time_cookie = cookie(-name=>'time', -value=>scalar localtime, -expires=>'+1y'); print header(-cookie => $time_cookie), start_html(-title=>'Cookie test'), h1('Cookie test'); if (my $time = cookie('time')) { print p("You last visited this page at $time"); } else { print p("You haven't visited this page before"); } print end_html; |
In this code we deal with two cookies. One that we read from the incoming HTTP header and one that we write to the outgoing HTTP header to be stored by the browser for next time. The code may be slightly confusing because it seems that we process them in the wrong order. We write the outgoing cookie before processing the incoming one. This is because we need to put the outgoing cookie into the HTTP header that we write back to the browser.
Our outgoing cookie has the name “time” and a value that is the current time. We also set it to expire in one year. The “cookie” function returns a string representation of this cookie which we can then use in our call to “header” using the “-cookie” parameter. The browser then takes this cookie and squirrels it away ready to return it to us the next time the user visits our site.
We then look to see whether there was a “time” cookie in the incoming HTTP header. If there is a cookie we extract the value and display it to the user. If our cookie doesn’t exist we display a message saying that the user hasn’t visited this site before. The next two figures show what you’ll see the first and second time that you visit this site.
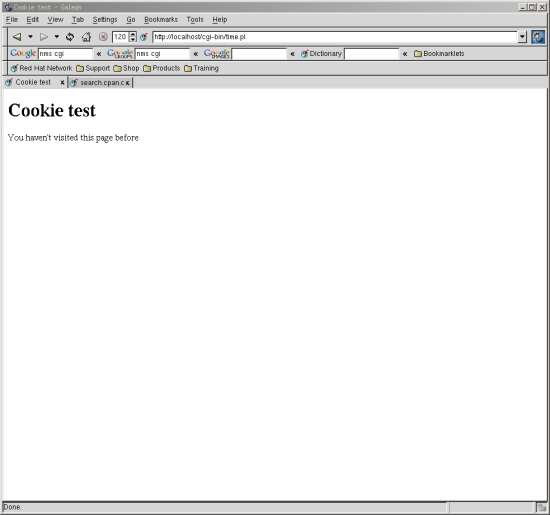
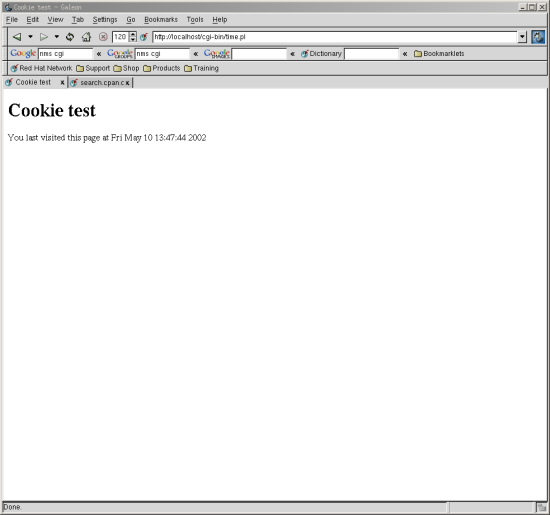
Most modern browsers allow you to look at your existing set of cookies (sometimes known as a “cookie jar”). In Galeon, it is the menu item Tools|Cookie…|View Cookies. You’ll initially see a list of sites and cookie names. Clicking on any item in the list will display the values associated with that cookie. The next figure shows the values associated with the time cookie that was created with our sample program. As you can see from the dialog box, you can also remove and block cookies from here.
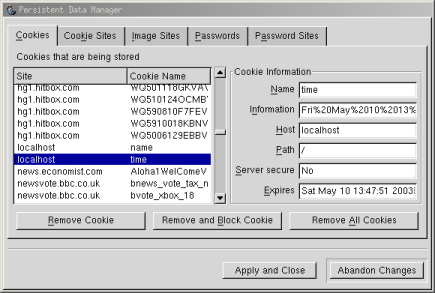
A more complex cookie example
The most commonly used method for storing session data is using cookies. The big advantage with cookies is that it doesn’t matter whether the user leaves your site and returns later. The data will still be there (unless, of course, the cookie has expired). It’s worth noting, however, that there are a significant number of Internet users who distrust cookies and turn off cookie support in their browsers. See the box “Cookies: The Spy In Your Browser” for more details on why they do this.
Having decided to use cookies, let’s have a look at a more complex example. This program allows a user to log on to your web site and get a personalised version of the site. This is similar to what you’ll see when you visit big shopping sites like Amazon and it welcomes you back by name. Here’s the code:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
#!/usr/bin/perl -wT use strict; use CGI ':standard'; my $name; my $logged; if (param('login')) { $logged = 1; $name = param('name'); print header(-cookie => cookie(-name=>'name', -value=>$name, -expires=>'+1y')); } elsif (param('logout')) { $logged = 0; $name = 'Guest'; print header(-cookie => cookie(-name=>'name', -value=>'', -expires=>'-1d')); } else { $logged = defined cookie('name'); $name = cookie('name') || 'Guest'; print header; } print start_html(-title => 'Cookies'); print h1('Cookies'); print p('This is a cookie test page'); $name =~ s/</</g; $name = b($name); print p("Hello $name"); print start_form; if ($logged) { print p(submit(-name=>'logout', -value=>'logout')); } else { print p('Enter your name: ', textfield(-name=>'name'), submit(-name=>'login', -value=>'Set name')); } print end_form; print end_html; |
In this example, we’re not only dealing with cookies, but we also have to deal with ordinary CGI parameters, in particular the name of the visitor.
The first time you visit this page you are welcomed as a guest as you can see in the first figure. If you have previously the site your name then you’ll see the second screen.
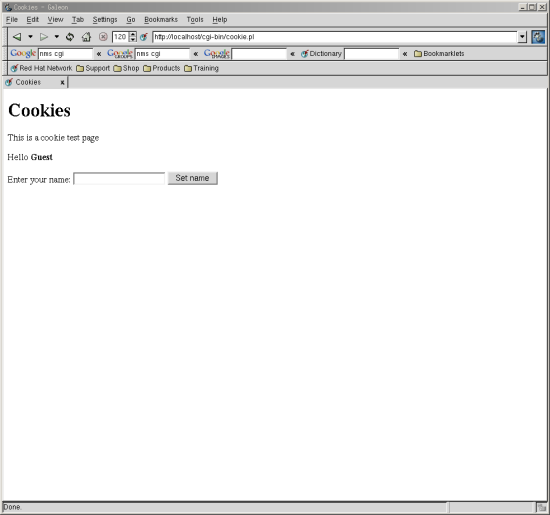

Most of the processing takes place in the three-pronged if/else code. If there is a “login” parameter, it means that there is no existing “name” cookie. We set a flag saying that the user is logged in, set the $name variable to the value of the “name” parameter and in the HTTP header we write a cookie containing the name. We set the expiry date (arbitrarily) to be a year in the future.
If there is a “logout” parameter, the user wants our site to forget their name. We set a flag to say that the use isn’t logged in and set the $name variable to the default value of “Guest”. Notice that the “cookie” function doesn’t explicitly support the deletion of cookies, so we get around that by setting a cookie that expires one day in the past.
If there are no CGI parameters, then the user is simply visiting our page. We work out whether or not they are logged in from the presence or absence of the “name” cookie and set a flag appropriately. We then print a plain HTTP header as there is no need to alter the cookie.
Having worked out whether or not the user is logged in and what name we should be using, we then display the web page. Depending on the state of the $logged flag, we decide whether to display a login form or a logout button.
There’s one slight change that could be made to this program. If the user visits our site and is already logged in, we do nothing to the cookie. This means that the cookie will always expire a year after the user logs in to the site. If we were to also update the cookie when a logged in user visited the site, then the cookie would always expire a year after the user’s most recent visit. Obviously the exact behaviour that you would implement is decided by the requirements of your site.
Getting HTML out of your Perl
Most of the web pages that we’ve created in this series have looked pretty dull. One reason for that is that they were just examples, but another reason is that putting too much complex HTML in your Perl code just makes for over-complex code. Even using the HTML functions within CGI.pm doesn’t really help.
Another similar problem is making your CGI-generated pages look the same as the rest of your site. You probably want navigation bars, copyright notices, logos and the like to match your other pages. And if your site design changes, you’ll need to change your Perl code to reflect that change. If you’re working on a larger site, it’s possible that the HTML pages are written by a completely different set of people to the CGI programs.
All of these problems can be solved by removing the HTML from your Perl code. You do this by using a templating system. See the box “Templating Systems In Perl” for a review of the systems available and and explanation of why I recommend the Template Toolkit.
As an example we’ll reuse the program we used two months ago as an example of form processing. The output from that program is shown in the next figure.
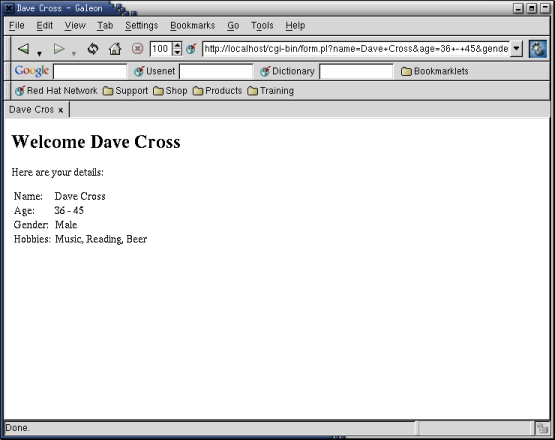
Here’s the new program that we’ll use.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
#!/usr/bin/perl -Tw use strict; use CGI ':standard'; use Template; my $name = param('name'); my $age = param('age'); my $gender = param('gender'); my @hobbies = param('hobby'); my $list; if (@hobbies) { $list = join ', ', @hobbies; } else { $list = 'None'; } my $t = Template->new; print header; $t->process('form.tt', { name => $name, age => $age, gender => $gender, hobbies => $list }) || die $t->error; |
As you can see, there is no HTML in the program at all. All of that is handled by the Template module. We load Template.pm at the start of the script and later on we create an instance of the class (Template.pm is an Object Oriented module) using its “new” method. We read the CGI parameters in exactly the same way that we always have and assing them to the same variables.
The actual display of the page is handled by the “process” function which is a method belonging to the Template class. We pass two parameters to the “process” method, the name of a file that contains our template and a reference to a hash which contains the data that we want to display. The “process” method inserts the data into the template and prints the result to STDOUT. If the template processing causes any kind of error then the program dies.
Let’s take a look at the contents of form.tt.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
<html> <head> <title>[% name %]</title> </head> <body> <h1>Welcome [% name %]</h1> <p>Here are your details:</p> <table> <tr><td>Name:</td> <td>[% name %]</td></tr> <tr><td>Age:</td> <td>[% age %]</td></tr> <tr><td>Gender:</td> <td>[% gender %]</td></tr> <tr><td>Hobbies:</td> <td>[% hobbies %]</td></tr> </table> </body> </html> |
As you can see, most of it is is just ordinary HTML. The only difference is the presence of [% … %] tags where you want the data to go. Inside the tags are the names of the data items that you want to display. These correspond to the keys in the hash of data that you passed to the “process” method.
The output that this template produces isn’t any prettier than the original form. In fact it’s exactly the same as the original form. But I hope you can see that by separating the processing from the presentation like this, it’s made things easier to handle. You can even have simple logic in the template. Let’s change our script slightly. Here’s the new version
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
#!/usr/bin/perl -Tw use strict; use CGI ':standard'; use Template; my $name = param('name'); my $age = param('age'); my $gender = param('gender'); my @hobbies = param('hobby'); my $t = Template->new; print header; $t->process('form2.tt', { name => $name, age => $age, gender => $gender, hobbies => \@hobbies }) || die $t->error; |
The only change we’ve made is that we no longer check on the number of hobbies and create a text list in the program. We now pass a reference to the list to the template processor.
We’ll also change the template.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
<html> <head> <title>[% name %]</title> </head> <body> <h1>Welcome [% name %]</h1> <p>Here are your details:</p> <table> <tr><td>Name:</td> <td>[% name %]</td></tr> <tr><td>Age:</td> <td>[% age %]</td></tr> <tr><td>Gender:</td> <td>[% gender %]</td></tr> <tr><td>Hobbies:</td> <td> [% IF hobbies.size %] <ul> [% FOREACH hobby = hobbies %] <li>[% hobby %]</li> [% END %] </ul> [% ELSE %] None [% END %] </td></tr> </table> </body> </html> |
We’ve added some logic to the template using simple conditional and looping constructs. As the “hobbies” template variable is now a list of items we can check the number of items in the list using the “.size” method. If the list is empty we display the word “None”, but if the list contains elements we create an unordered list of the items. The next figure shows the results of using this template.
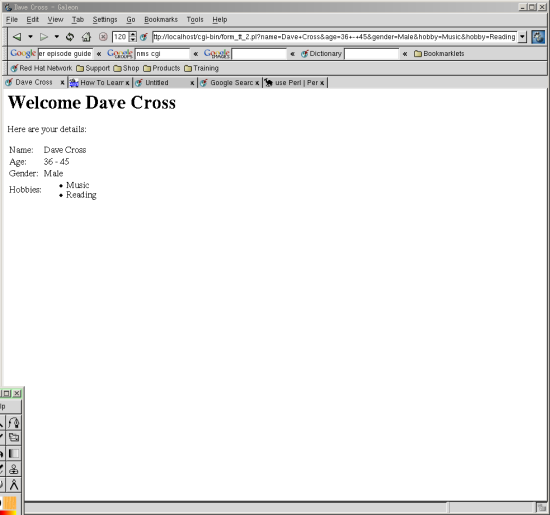
We’ve barely scratched the surface of what the Template Toolkit can do for you, but it’s guaranteed to make the maintenance of your code far easier. I’d really recommend that you look at using some sort of templating system for all of your CGI programs.
Conclusion
So that concludes our three-month introduction to CGI programming. I hope it’s started you thinking about the kinds of things that you can do with this technology. If you’d like to learn more, the two best books on the subject are probably “CGI Programming with Perl” by Guerlich, Gundavaram and Birznieks and “Writing CGI Applications with Perl” by Meltzer and Michalski.
