Perl Hacks: Just another Perl hacker’s blog
-

Collecting talks
I gave my first public talk sometime between the 22nd and 24th September 2000. It was at the first YAPC::Europe which was held in London between those dates. I can’t be any more precise because the schedule is no longer online and memory fades. I can, however, tell you that the talk was a disaster.…
-

Amazon Links and Buttons
I’ve spent more than a reasonable amount of time thinking about Amazon links over the last three or four years. It started with the Perl School web site. Obviously, I knew that the book page needed a link to Amazon – so people could buy the books if they wanted to – but that’s complicated…
-
Pointless personal side projects
I can’t be the only programmer who does this. You’re looking for an online service to fill some need in your life. You look at three or four competing products and they all get close but none of them do everything you want. Or maybe they do tick all the boxes but they cost that…
-

The present isn’t evenly distributed either
The future is already here – it’s just not very evenly distributed – William Gibson The quotation above was used by Tim O’Reilly a lot around the time that Web 2.0 got going. Over recent months, I’ve had a few experiences that have made it clear to me that even the present isn’t particularly evenly…
-
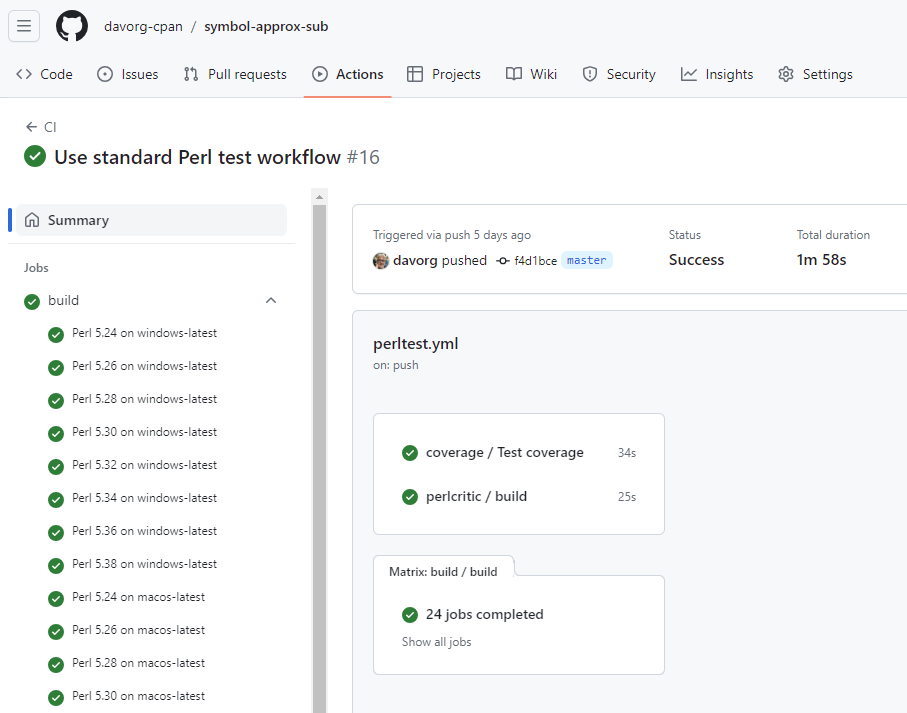
GitHub Actions for Perl Development
You might remember that I’ve been taking an interest in GitHub Actions for the last year or so (I even wrote a book on the subject). And at the Perl Conference in Toronto last summer I gave a talk called “GitHub Actions for Perl Development” (here are the slides and the video). During that talk,…