Tag: moose
-
Training Debrief
During the second week of February, I ran my (approximately) annual public Perl training courses in association with FlossUK. Things were organised slightly differently this year. Previously we’ve run two two-day “general purpose” courses – one on Intermediate Perl and one on Advanced Perl. This year we ran four courses, each of which were on…
-
Training Courses – More Details
Last week I mentioned the public training courses that I’ll be running in London next February. A couple of people got in touch and asked if I had more details of the contents of the courses. That makes sense of course, I don’t expect people to pay £300 for a days training without knowing a…
-
Public Training in London – February 2016
For several years I’ve been running an annual set of public training courses in London in conjunction with FLOSS UK (formerly known as UKUUG). For various scheduling reasons, we didn’t get round to running any this year, but we have already made plans for next year. I’ll be running five days of training in central…
-
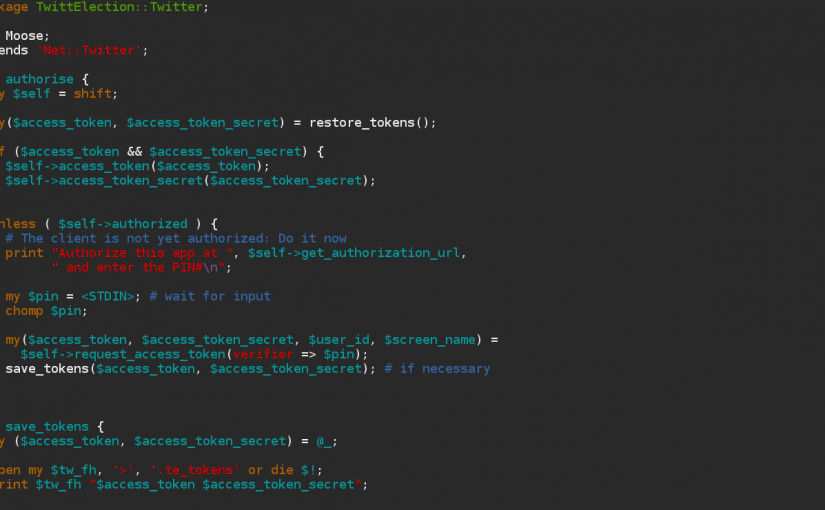
Moose Course This Saturday
I’m running another Perl School this Saturday (6th April). This time the subject is Object Oriented Programming with Perl and Moose. I ran a two-hour taster version of this course at the London Perl Workshop back in November, but this is the full six-hour version. Tickets are £30 each. The course is run at Google…
-
Perl School 3
Yesterday was the third Perl School. Twenty-one students converged on Google Campus in London and spend a day learning about Moose. The day seemed to go well. People asked intelligent questions and seemed to understand what I was telling them. Hopefully the feedback forms will tell a similar story. No more training now for a…