Perl Hacks: Just another Perl hacker’s blog
-
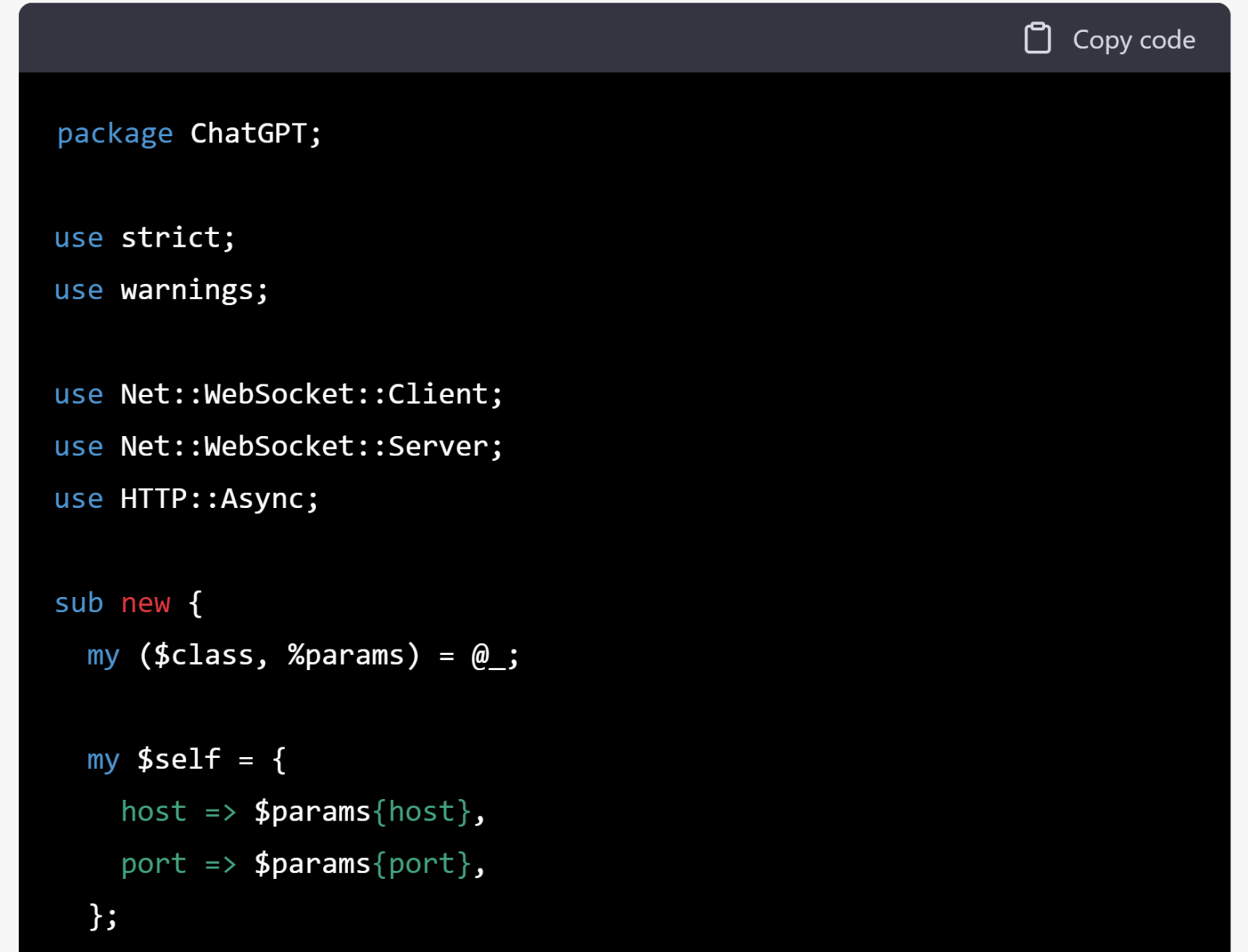
Writing a CPAN module that talks to ChatGPT
ChatGPT exposes an API, but there’s no CPAN module for taking advantage of that. Let’s put that right (with help from ChatGPT)… Write a Perl CPAN module for connecting to a ChatGPT server To create a Perl CPAN module for connecting to a ChatGPT server, you will need to have Perl and the necessary dependencies…
-
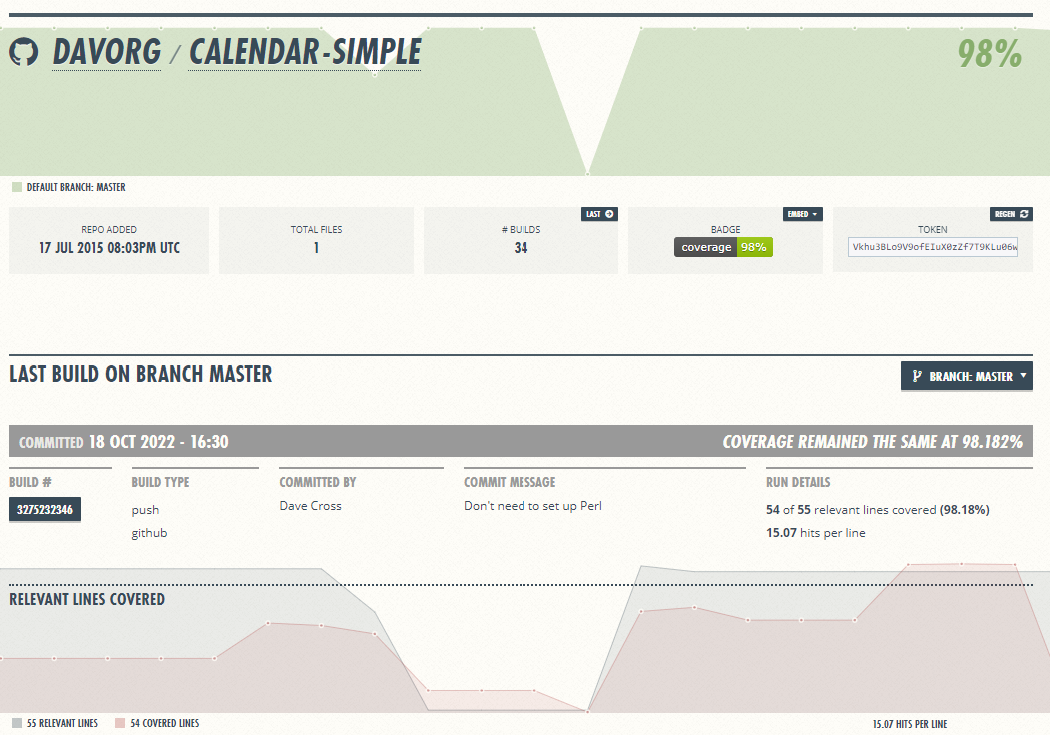
Containers for Coverage
I’ve been building Docker containers again. And I think you’ll find this one a little more useful than the Perlanet one I wrote about a couple of weeks ago. Several years ago I got into Travis CI and set up lots of my GitHub repos so they automatically ran the tests each time I committed…
-
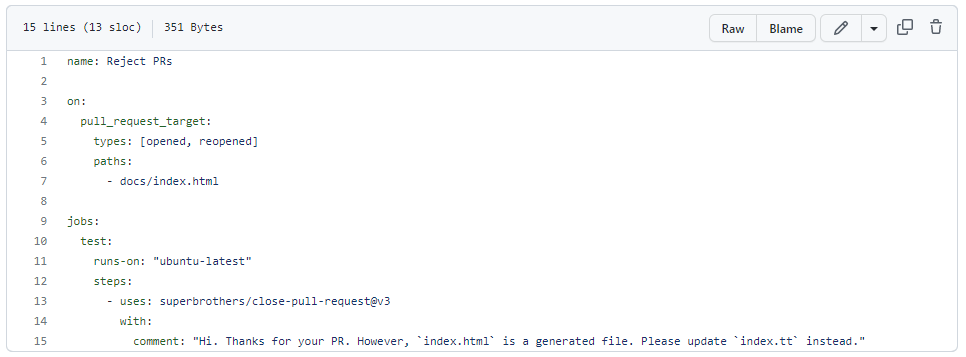
Not that PR, thanks
It’s October. And that means that Hacktoberfest has started. If you can get four pull requests accepted on other people’s code repositories during October then you can win a t-shirt. In many ways, I think it’s a great idea. It encourages people to get involved in open source software. But in other ways, it can…
-
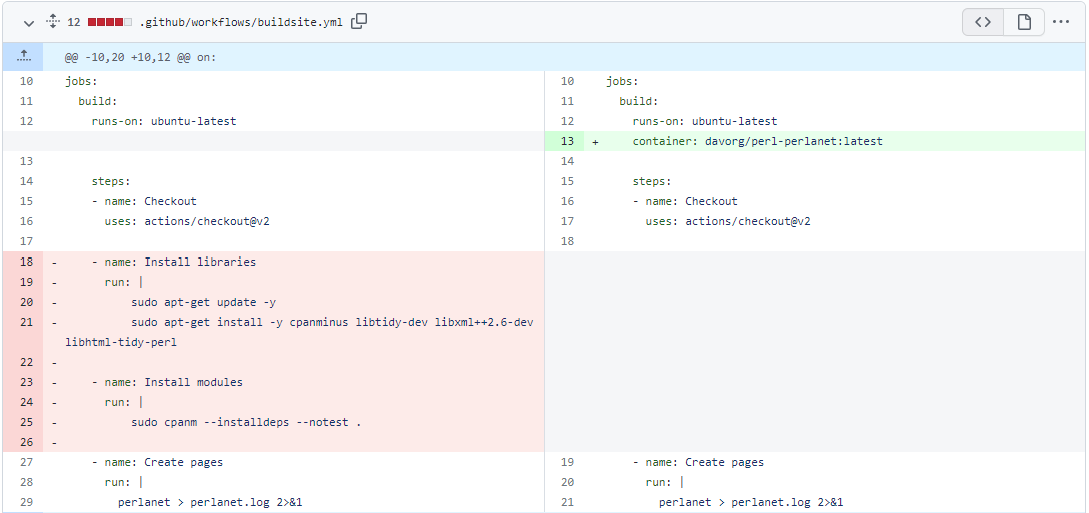
Building a Perlanet Container
I’m a dinosaur who still believes that web feeds are a pretty neat idea. I wrote and maintain perlanet (a Perl program for aggregating web feeds into a new feed – and building a web site based on that new feed) and I use it to build a few sites on topics I’m interested in.…
-
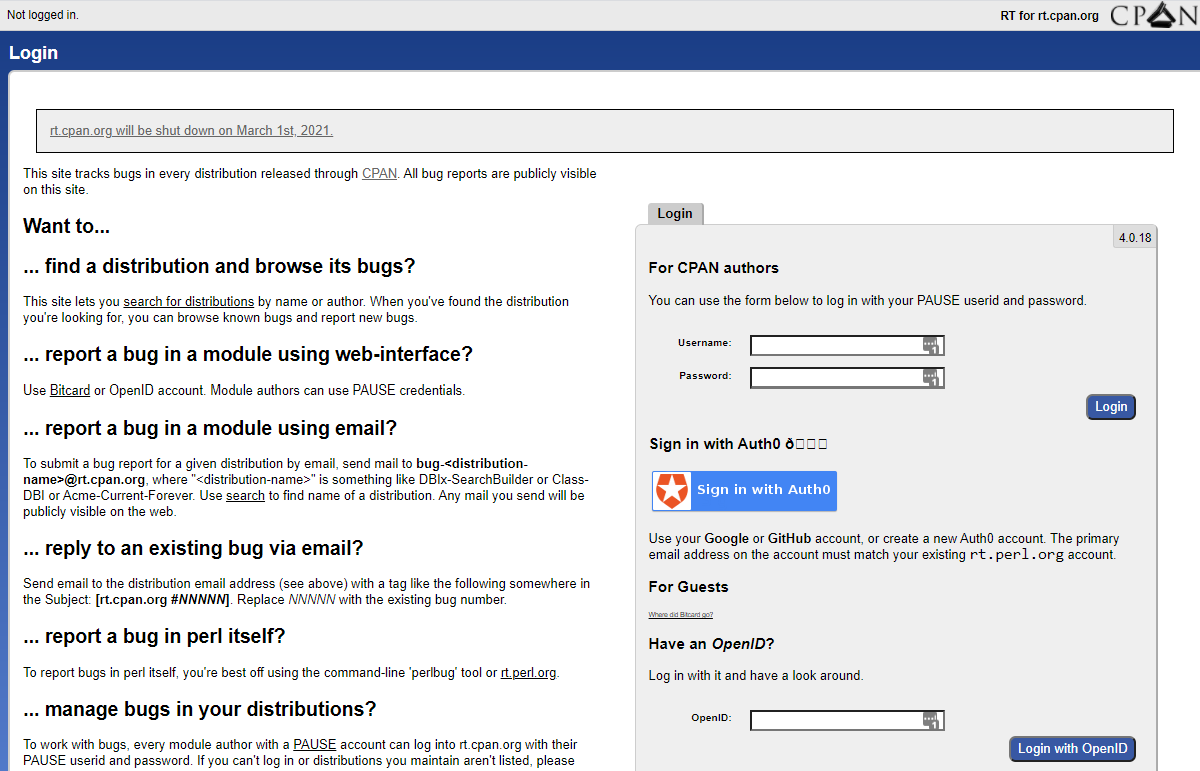
Replacing CPAN RT
[Update: the CPAN Request Tracker was saved. It’s now run by a new team of volunteers and none of my suggestions below are required.] Two weeks ago, we learned that the CPAN Request Tracker was closing down early next year. I proposed a plan that CPAN authors could follow to ensure that their users can…